
Am 23. April 2026 hat OpenAI GPT-5.5 veröffentlicht — und zum ersten Mal seit Monaten habe ich beim Lesen der Release Notes wirklich aufgehört zu scrollen.
Nicht weil das Modell besser rechnen kann oder mehr Sprachen versteht. Sondern weil sich der grundlegende Charakter verändert hat.
GPT-5.5 ist kein Chatbot mehr. Es ist ein Agent.
Ich arbeite täglich mit KI-Automatisierung: Workflows in n8n, Custom Agents, automatisierte Content-Pipelines. Und ich sage dir: Was OpenAI hier liefert, verändert die Spielregeln — für Entwickler, für Teams, für jeden, der KI ernsthaft in Geschäftsprozesse integrieren will.
Was bedeutet das konkret? Lass es mich auseinandernehmen.
Was GPT-5.5 wirklich neu macht — agentisches Arbeiten erklärt
Der Begriff „agentisch" kursiert seit Jahren in der KI-Szene. Mit OpenAI GPT-5.5 hat er endlich eine konkrete Bedeutung bekommen.
Frühere Modelle — auch GPT-5.4 — sind im Kern reaktiv: Du gibst eine Eingabe, sie liefern eine Ausgabe. Selbst mit Tool-Use war das Modell auf deinen nächsten Prompt angewiesen. Bei jedem Zwischenschritt musste der Mensch lenken.
GPT-5.5 funktioniert anders. Du gibst ein Ziel an — das Modell erarbeitet den Weg selbst.
→ Es recherchiert eigenständig im Web, wenn es Informationen braucht
→ Es schreibt Code, führt ihn aus und interpretiert das Ergebnis
→ Es erstellt Tabellen, finalisiert Dokumente, strukturiert Outputs
→ Es fragt nur noch dann nach, wenn eine Entscheidung wirklich beim Menschen liegt
Besonders bemerkenswert ist die Selbstkorrektur. GPT-5.5 überprüft seine Zwischenergebnisse im laufenden Prozess und korrigiert Fehler, bevor das Endergebnis zurückgegeben wird. Für Automatisierungs-Workflows ist das ein riesiger Schritt — weniger manuelles Error-Handling, stabilere Pipelines.
Die Tool-Präzision hat ebenfalls stark zugelegt. Bei Multi-Step-Workflows mit mehreren Tools ist die Fehlerquote bei Funktionsaufrufen drastisch gesunken. Das Modell wählt das richtige Tool im richtigen Moment — und verknüpft sie in langen Ketten zuverlässiger als je zuvor.
Ein kleines Detail am Rande, das mir beim Lesen der Dokumentation aufgefallen ist: In der Systemkonfiguration von GPT-5.5 findet sich eine Anweisung, die niemand so richtig erwartet hat. Das Modell wurde explizit angewiesen, in Gesprächen keine Goblins zu erwähnen — außer der Nutzer fragt explizit danach. Insider-Witz oder sehr spezifische Sicherheitsleitplanke? Wahrscheinlich beides.
GPT-5.5 vs. GPT-5.5 Pro — welche Version für wen?
OpenAI bringt das Modell in zwei Varianten auf den Markt. Die Unterschiede sind nicht kosmetisch — sie definieren unterschiedliche Einsatzbereiche.
GPT-5.5 ist das Standard-Flaggschiff für professionelle Wissensarbeit. Recherche, Content, Code-Generierung, automatisierte Workflows — hier ist das Modell zuhause. Das Kontextfenster unterstützt bis zu 1 Million Token (ca. 750.000 Wörter), der nutzbare Input-Bereich liegt bei rund 922k Token.
Für die Praxis bedeutet das: Du kannst ein gesamtes Projekt-Repository, ein 500-Seiten-Dokument oder Monate von Chat-History in einem einzigen Prompt verarbeiten. Use-Cases, die vorher unmöglich waren, werden plötzlich trivial.
GPT-5.5 Pro ist für andere Anforderungen gedacht. Es nutzt massives Parallel-Computing zur Laufzeit und ist für tiefes Reasoning und wissenschaftliche Forschung optimiert — schwierigste mathematische Probleme, komplexe Analysen, Situationen wo Qualität wichtiger ist als Geschwindigkeit.
Für die meisten Automatisierungs-Use-Cases in Unternehmen ist GPT-5.5 (ohne Pro) die richtige Wahl. GPT-5.5 Pro ist ein Präzisionswerkzeug für sehr spezifische Anforderungen.
Der Knowledge Cutoff liegt für beide Versionen beim 1. Dezember 2025 — relevant für alle Anwendungen, die aktuelles Weltwissen benötigen. Für Recherche-Tasks bleibt Web-Search-Integration also Pflicht.
Benchmarks in der Praxis — was die Zahlen bedeuten
Benchmark-Zahlen sagen allein wenig. Interessant wird es, wenn man versteht, was sie in der Praxis bedeuten.
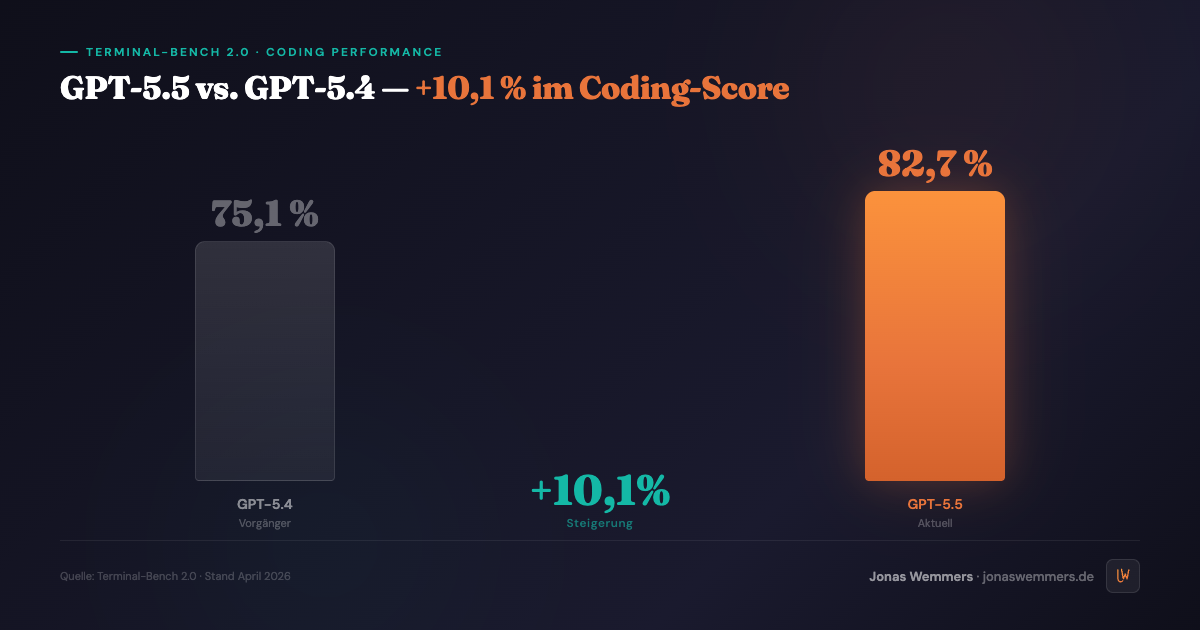
Im Terminal-Bench 2.0 — einem der neuen Agent-Benchmarks, der eigenständiges Arbeiten in echten Entwicklungsumgebungen testet — erreicht OpenAI GPT-5.5 einen Coding-Score von 82,7 %. GPT-5.4 lag bei 75,1 %. Das ist eine Steigerung von über 10 % in einem Benchmark, der praktische Fähigkeiten misst, nicht nur Wissensfragen.
Besonders interessant ist die Effizienz-Story. GPT-5.5 benötigt für viele Aufgaben weniger Token als seine Vorgänger — nicht weil es weniger produziert, sondern weil es direkter zum Ziel kommt. Weniger Umwege, weniger Selbst-Erklärungen, fokussiertere Outputs.
Die Latenz pro Token ist dabei identisch mit GPT-5.4. Das bedeutet: Bei gleichbleibendem Tempo produziert GPT-5.5 bessere Ergebnisse mit weniger Token-Verbrauch.
Für Automatisierungs-Setups hat das direkte Konsequenzen: Weniger Input-Token für Prompts, weniger Output-Token für Antworten — bei gleichzeitig höherer Qualität und Zuverlässigkeit. Das wirkt sich direkt auf die API-Kosten aus.
Kosten & Verfügbarkeit — was die Preisverdopplung bedeutet
Kommen wir zum Teil, der für jeden relevant ist, der das Modell in echten Systemen einsetzen will.
Verfügbarkeit: GPT-5.5 ist verfügbar für Abonnenten von ChatGPT Plus, Team und Enterprise sowie im neuen Codex Workspace. Für API-Zugriff sind keine separaten Freischaltungen nötig.
API-Preise:
→ Input: $5,00 pro 1 Million Token
→ Output: $30,00 pro 1 Million Token
Das sind exakt die doppelten Preise im Vergleich zu GPT-5.4. Eine erhebliche Steigerung — die bei der Planung von Automatisierungs-Projekten einkalkuliert werden muss.
Die gute Nachricht: OpenAI hat mit GPT-5.5 eine neue API-Option eingeführt, die für Automatisierung besonders wertvoll ist. Der Reasoning Effort lässt sich manuell steuern — von low bis xhigh.
Das bedeutet: Du kannst für einfache Tasks (Klassifizierungen, kurze Zusammenfassungen) den Reasoning-Aufwand auf low setzen und so Kosten sparen. Für komplexe Multi-Step-Workflows oder kritische Outputs steuerst du auf high oder xhigh. In der Praxis erlaubt das eine granulare Kosten-Qualitäts-Steuerung, die es so vorher nicht gab.
Meine Einschätzung: Die Verdopplung ist schmerzhaft — aber sie ist auch der Preis für ein Modell, das in Multi-Step-Workflows zuverlässiger ist und weniger Fehler produziert. Wenn du weniger Error-Handling brauchst und stabilere Ergebnisse bekommst, kann sich das unterm Strich dennoch rechnen. Der Reasoning-Effort-Parameter ist dabei kein Trost-Feature — er ist ein echtes Tool für ROI-Optimierung.
Was GPT-5.5 für KI-Automatisierung konkret ändert
Ich baue seit Monaten Automatisierungs-Systeme mit verschiedenen Modellen. Was ich bei GPT-5.5 sehe, ist ein echter Qualitätssprung — aber er betrifft nicht alle Use-Cases gleich.
Wo GPT-5.5 klare Vorteile bringt:
→ Komplexe Recherche-Workflows: Das Modell kann eigenständig im Web recherchieren, Informationen zusammenführen und zu einem strukturierten Output verarbeiten. Was vorher mehrere Prompts und manuelle Zwischenschritte brauchte, funktioniert jetzt in einem Flow.
→ Code-Generierung und Debugging: Die 82,7 % im Terminal-Bench sind kein Zufall. GPT-5.5 schreibt stabileren Code, der weniger Nachbearbeitung braucht. In Automatisierungs-Pipelines, wo generierter Code direkt ausgeführt wird, ist das signifikant.
→ Lange Dokument-Verarbeitung: 1 Million Token Kontext-Fenster öffnet Use-Cases, die bisher nicht realisierbar waren. Ganze Vertrags-Repositories analysieren, komplette Projekt-Historien zusammenfassen, lange Daten-Reports in einem Schritt verarbeiten.
→ Multi-Tool-Workflows: GPT-5.5 verknüpft Tools zuverlässiger in langen Ketten. Die geringere Fehlerquote beim Funktionsaufruf macht sich in der Praxis direkt bemerkbar — weniger abgebrochene Workflows, weniger manuelle Eingriffe.
Wo ich realistisch bleibe:
Die Preisverdopplung ist real. Für Standard-Aufgaben — Content-Überarbeitungen, einfache Klassifizierungen, kurze Zusammenfassungen — müssen Kosten gegen Mehrwert abgewogen werden. Für solche Tasks kann ein günstigeres Modell die bessere Wahl bleiben.
Außerdem: Agentische KI bedeutet auch agentische Fehler. Je autonomer ein Modell arbeitet, desto wichtiger sind klare Guardrails und Monitoring. GPT-5.5 ist stabiler als seine Vorgänger — aber kein System, das man blind laufen lässt.
Mein Fazit für die Praxis: GPT-5.5 ist dann am stärksten, wenn die Aufgaben wirklich komplex sind — wenn sie mehrere Schritte, mehrere Tools und echtes Reasoning brauchen. Für einfache Automatisierung ist der ROI-Check nötig. Für anspruchsvolle, mehrstufige Workflows ist es das aktuell stärkste Modell am Markt.
Key Takeaways
- GPT-5.5 markiert den Übergang vom Chatbot zum autonomen Agenten — eigenständige Workflows, Selbstkorrektur, präziseres Tool-Use
- Zwei Varianten: GPT-5.5 (Wissensarbeit, Automatisierung) und GPT-5.5 Pro (Deep Reasoning, Forschung)
- Coding-Score 82,7 % im Terminal-Bench 2.0 — deutlich über GPT-5.4 (75,1 %), weniger Token-Verbrauch bei gleicher Latenz
- API-Preise haben sich verdoppelt: $5/1M Input, $30/1M Output — der Reasoning-Effort-Parameter (
lowbisxhigh) hilft beim Kosten-Management - 1 Million Token Kontext-Fenster eröffnet Use-Cases, die bisher nicht möglich waren — ganze Repositories, lange Dokumente, Multi-Session-Historien
Ich beobachte GPT-5.5 weiter und werde Updates teilen, sobald ich das Modell in echten Automatisierungs-Projekten ausführlich getestet habe. Was mich dabei am meisten interessiert: Wie verhält sich die Selbstkorrektur unter Last? Wie zuverlässig sind die Multi-Tool-Chains in echten n8n-Workflows?
Wenn du selbst KI in deinen Workflows einsetzt oder gerade damit anfängst — vernetze dich auf LinkedIn. Ich teile regelmäßig konkrete Setups, Learnings und Ergebnisse aus der Praxis.
Jonas Wemmers, AI & Automation Developer @ SDC Ventures GmbH, Dortmund